
Recently Updated
Help
CancelIf you are a Data Owner, once you have created a collection you can proceed to add items and documents to your collection. A convenient way to do this is to upload a zip file containing your documents. You can do this by going to the main page for your collection and clicking on “Import Zip”.
The zip file must be smaller than 1GB. If your data is larger than this, you can upload it in batches – each new zip file will be added to the existing data in the collection.
Zip File Structure
When you upload a zip file, one or more items will be created and one or more files will be associated with these as documents. Depending on your settings, and on the structure of your data, the way that these items are made can vary.
In the simplest case, you will have one document per item; for example, if you have a collection of text documents, each with a different filename and the same extension (.txt). In this case, one item is created per file, and that file is attached as a document to that item. The name of the item will be the base name of the file (everything up to the extension).
If you have more than one document per item, they can be grouped in two ways: by directory, or by the file base name.
Grouping by Directory Name
If you have a number of documents for each item you can make a different directory for each item and store the files in that directory. In the example here (from the MAVA collection) the directory names are s1, s2 etc and each contains a collection of documents. 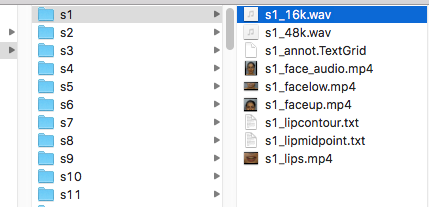
Given this structure, you can create one item for each directory and attach the documents to that item.
Grouping by File Name
Another common case is to have a group of files with the same base name but different extensions, as in this example:
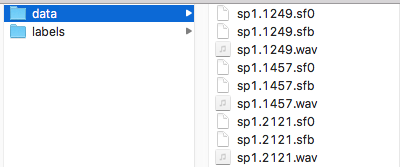
In this case, the files with the same name can be grouped together to be attached to the same item. The name of the item is the common base name (eg. sp1.1249).
Import Settings
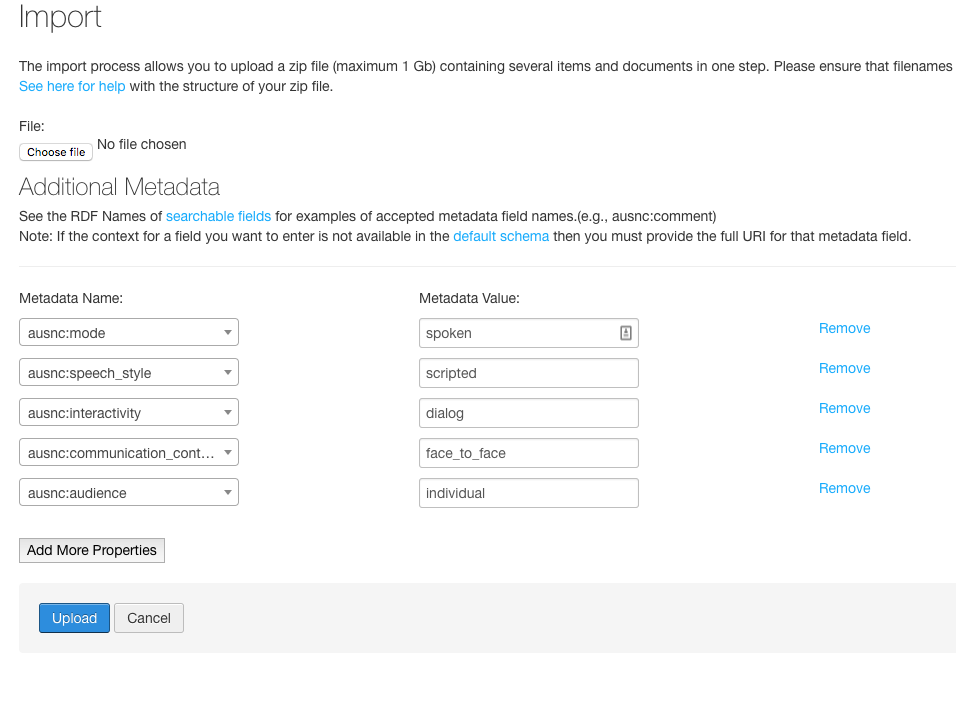
On the zip import page you have the option to select a zip file for upload and to set a number of metadata fields. These metadata fields will be set for all of the items that you import from this zip file. Some common fields are pre-populated, you should modify their values or remove them as appropriate. These fields are used on most of the Alveo collections so adding values if possible may help people find your data in searches. Possible values for these fields include:
- ausnc:mode – spoken, written, signed
- ausnc:speech-style – scripted, spontaneous
- ausnc:interactivity – dialog, monolog
- ausnc:communication_context – face_to_face, distance
- ausnc:audience – individual, group
Further metadata fields can be added as needed
Import Preview
When you have completed filling out the metadata for your items, click on the blue Upload button and your zip file will be submitted. It will be unpacked and you will be shown a preview of the import. You can change various options and refresh to update the preview. At this point your data has not yet been imported, you must confirm the settings first.
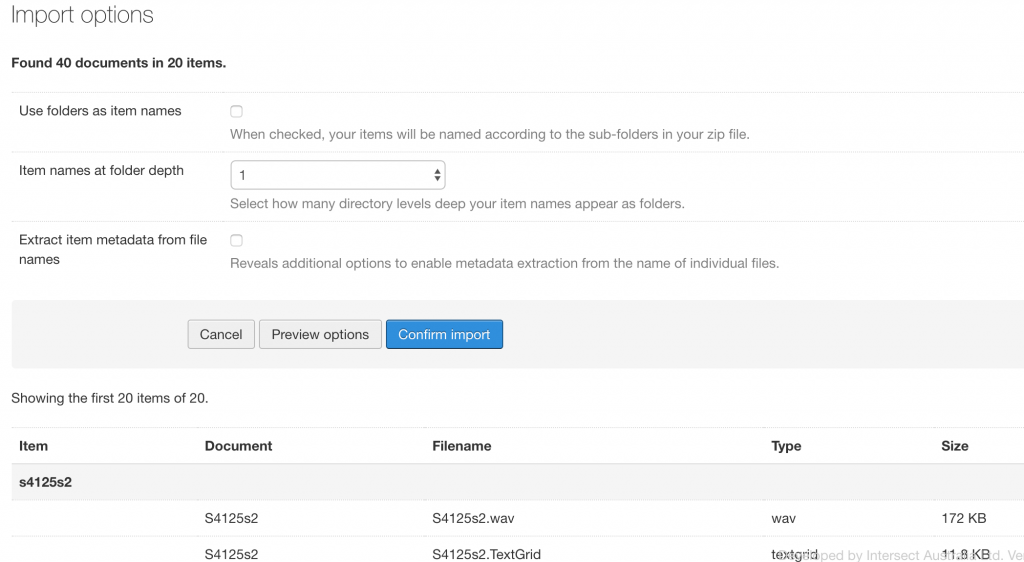
The preview shows a the number of documents and items that would be created, and allows you to change some settings to modify how the files will be imported. Below the form, you will see a preview of the items and their documents.
The default behaviour is to look for common base names in your files and group them into items. This is shown above with S4125s2.wav and S4125s2.TextGrid being attached to an item named S4125s2. However, you can change the import options and update the preview.
Use folders as item names if this is checked, folder names will be used as item names. The following drop-down selector allows you to nominate what depth of folder should be looked for. If you check this box and click on Preview options the page will refresh and show you how your import will look under those settings.
Extract item metadata from filenames allows you to parse metadata from item filenames in a simple manner. If you check this box, a number of other options will appear:
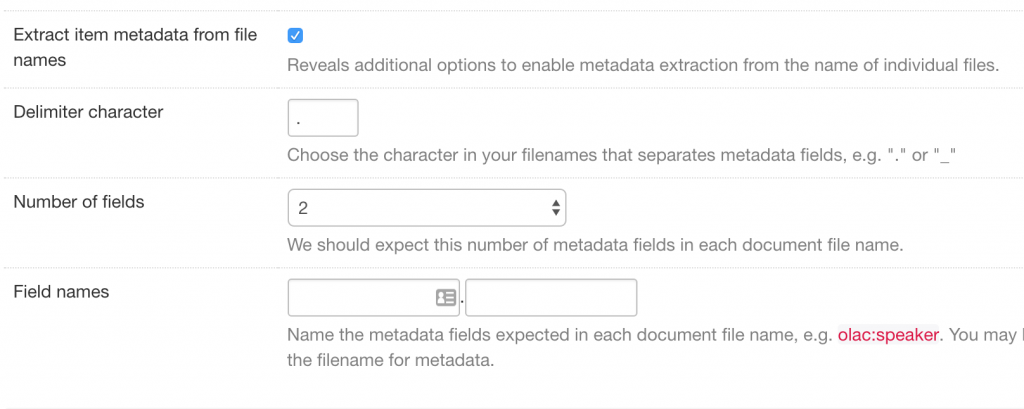
You must specify a delimiter character and the number of fields to split the filename into. For example, if your files are named sp1.1234.wav, where sp1 is the speaker identifier and 1234 is the prompt that was read by the speaker you could specify a delimiter of “.” and two fields. You can then specify the field names: olac:speaker is the metadata property name used in Alveo for the speaker associated with an item. We could also use austalk:prompt for the prompt as that is used in the Austalk collection. With these settings, the filename will be parsed for each item to extract the appropriate metadata value.
Again, once you click on Preview options the page will update to show the effect of your settings. You will see a preview of the metadata values that have been extracted from your filenames.
Once you are happy with the preview of your import, click on Confirm Import and the import job will be processed. As import can take some time, your items will not be available immediately, they will appear as they are imported. To view them, go to the Discover page and select your new collection, refresh the page until all of your items appear.
- Alveo Documentation
- Getting Access to Alveo and Galaxy
- Accessing Alveo
- Accepting Licences to Access Collections
- What’s an API Key?
- Accessing Galaxy on Alveo
- Operation Basics
- Alveo Data Structures
- Discovering and Searching the Collections
- Browsing the Collections
- Searching and Selecting Items in the Collections
- Saving Your Search Results to an Item List
- Using and Saving Your Search History
- Viewing and Sharing Item Lists
- Analysing Data
- Concordance and Word Frequency
- Transferring Data to Galaxy for Processing
- Using Alveo Data with EMU/R
- Downloading Alveo Data to Your Computer
- Using Voyant Tools
- Adding Data to Alveo
- Create a Collection
- Uploading Data to a Collection
- Annotation Contributions
- User Administration Functions
- Updating Your Account Details
- Reporting an Alveo Issue
- HTTP API Reference