
This is Part 4 of a four-part tutorial in using Alveo. You can find the outline of the tutorial, and links to the other three parts on the Tutorials page. This Part will cover writing workflows in Galaxy, running workflows over single or multiple datasets, sharing workflows with others, and using other people’s shared workflows.
Introduction to Workflows
The real power of Galaxy is its ability to run tools as part of a predefined Workflow. Workflows allow you to run multiple datasets through a predefined chain of tools, rather than having to run each tool over each subsequent file manually. After you design a workflow, you can run it over a dataset or a collection of datasets, or you can continue to modify it, and you can even share the workflow with other Alveo users so that your experiments can be repeated and your results replicated.
Creating a Workflow
Workflows are created using a visual editor. To access the editor, select Workflows from the bottom of the Toolshed and then select Switch to workflow management view.

This is where your workflows will be listed when you have created them. It also lists workflows that other Alveo users have shared. To create your first, select Create new workflow, and in the next window, give it a meaningful name.
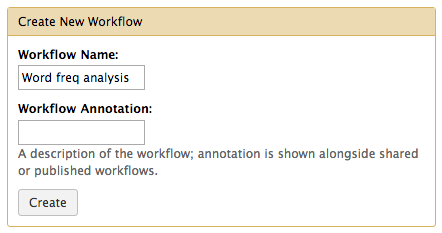
Editing a workflow
After you click Create you will be taken to the Workflow Canvas, which is like a virtual desktop in which tools can be individually configured, moved around and linked to one another with pipelines via their connectors.
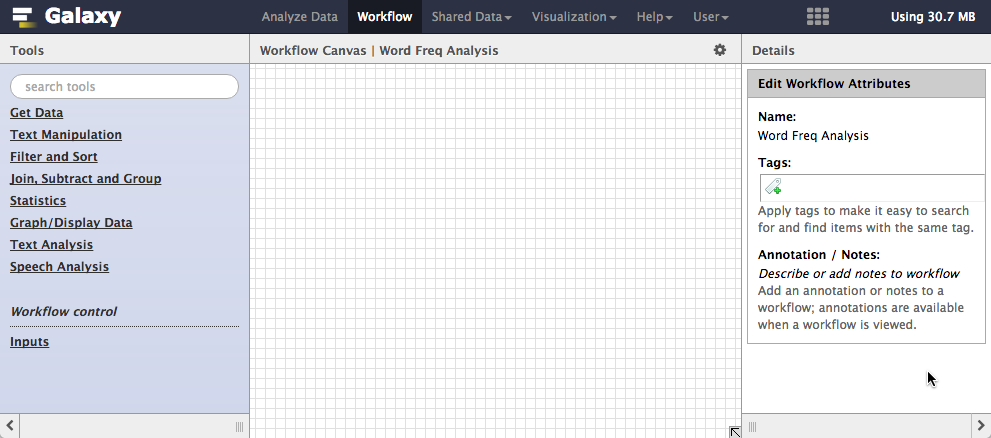
Notice that in the left pane, all the same tools are present and in the same categories as they were when you applied them to datafiles in Module 3, except this time, when you click on a tool, rather than taking you to a page where you run the tool over a datafile, the tool will appear on the canvas and can be joined to other tools and individually configured.
In addition to the tools that you saw in Module 3, there is one important additional tool that only occurs in the Workflow Canvas, called Inputs, under a heading Workflow control.

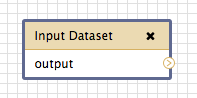
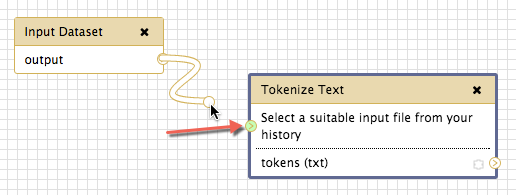
This tool is how you tell the workflow where to begin. Start by clicking on Inputs, then Input dataset, and notice that a block appears on the canvas. This block is a schematic representation of your input data file within the workflow. The Input tool doesn’t have much in the way of configuration associated with it, but one important thing it does have is its connector, represented by a small arrow on the right side of the tool. The Input Dataset tool only has one connector, pointing out, because it doesn’t take any other input. Instead, when you run the workflow, you will be asked to provide this input file (or collection of files).
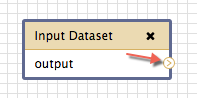
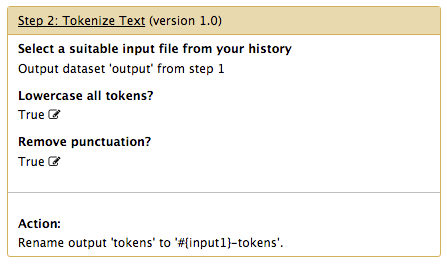
Now select another tool to bring into the workflow. Let’s take the Tokenize Text tool within the Text Analysis category. Click it and the tool will appear on the canvas. You will see that this tool has two connectors: one on the left side pointing into the tool, and one on the right side pointing out. The first is used to determine the tool’s input, and the second is where its output is sent. Similarly, within the tool, the text above the line describes the input expected for this tool, and the text below the line describes what the output will look like.
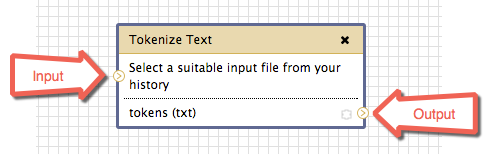
Pipelines and Connectors
If you click-and-hold on the output arrow of the Input Dataset tool and drag somewhere, you will notice a pipeline appearing. This pipeline is used to connect tools together. Direct the input dataset into the Tokenizer by dragging this pipeline to the Tokenize Text tool’s input connector.
| Tutorial Task 8: Create a workflow replicating the order of tools that you ran in Module 3: Input, Tokenize Text, Part of Speech Tagging and, finally, Frequency List. The position of the tools on the canvas is not important; what is important is the order in which the tools are connected to each other by the pipelines. Your workflow should look like this: 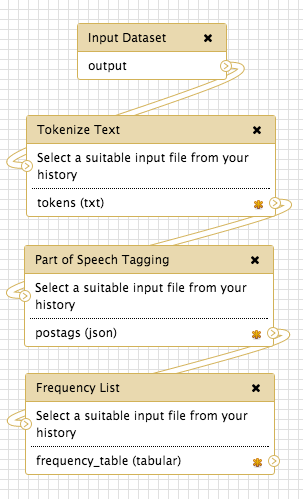 Note: While the Sort tool is available in the workflow canvas, it is not able to be correctly configured, meaning that the output datasets will need to be sorted outside of the workflow. | |—|
Note: While the Sort tool is available in the workflow canvas, it is not able to be correctly configured, meaning that the output datasets will need to be sorted outside of the workflow. | |—|
Tool options
If a tool has options when you run them individually in Galaxy, these options are also available for you to configure in the workflow. For example, the Tokenize Text tool allows you to change all tokens to lowercase, and to remove any punctuation. In the workflow, these options appear as checkboxes in the right sidebar, called Details, when the tool is selected.
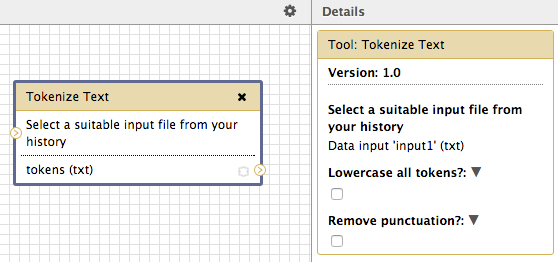
In addition to being able to set a tool’s options in the workflow editor, you also have additional functionality in the details sidebar under the categories Edit Step Actions and Edit Step Attributes. The latter allows you to annotate the tool with a description to remind you of what this tool will do. This annotation will be displayed next to each tool when you run it later, and will also be displayed next to that tool when others view the workflow if you decide to share it.
The Edit Step Actions box provides you with the ability to modify such settings as the output filename. You can name the output of any tool anything you like, or you can set it to a variable that you can enter when you run the workflow. You can also set the tool to name the output on the basis of the input filename. Select Rename dataset from the dropdown menu and click Create. Then in the New output name: field, enter #{input1} and then some suffix such as -tokens for the Tokenizer tool.
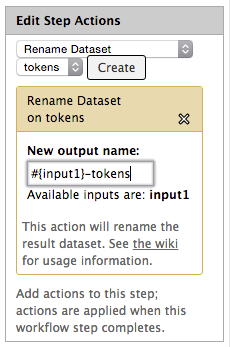
If you do this for every tool in your workflow, then each dataset will be named for the tools that it has been run through, and the specific order. For example, an output filename such asCooee-1780s-tokens-POS-freq indicates that it began with the dataset Cooee-1780s, and it was run through the Tokenize tool, the Part of Speech Tagging tool and the Frequency List tool.
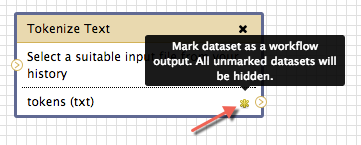
An additional option is to mark the tool’s output datasets as Workflow Outputs. If this option is checked for a tool, then its output will appear in your history sidebar as a dataset when the workflow is complete. If it is not marked, then it is treated as an intermediary stage in the workflow and will be removed from the history. In other words, the file is only kept temporarily and only so long as it is used by other tools in the workflow. Unless you have many tools in a single workflow, it is worthwhile marking them all as workflow outputs, so that if anything goes wrong (such as if a tool behaves differently to how you expect) then you have a digital paper trail to track the errors.
| Tutorial Task 9: Modify your workflow so that each tool is configured correctly (for example, the Tokenizer will remove punctuation), the output names are meaningful and based on the input filename (using the form #{input1}-tokens), and so that it returns only the result of the Frequency Count tool. | |—|
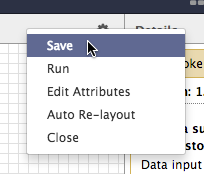
Finally, when you are finished editing a workflow, select Save from the gear icon.
Running Workflows
Workflows can be run in Galaxy just like any other tools, except that they consist of a number of tools internally, and in the history each individual tool will occur as its own ‘job’.
At the bottom of the Tools pane under Workflows, click All workflows. This will take you to a page which lists all workflows that you either created yourself, or that have been shared with you by others (more on sharing workflows with others later). Click on the workflow that you just defined, and you will see a page similar to that when you select an individual tool to run.

Select the dataset over which to run your workflow by clicking on the Input dataset tool, and selecting the dataset from the drop-down list. Note that this drop-down list displays files in your currently active history. If your desired dataset is in a different history, you must first switch to that history before running the workflow.
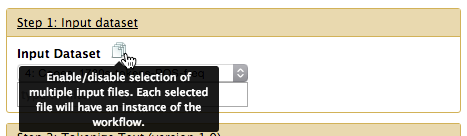
If you want to run your workflow over multiple input datasets, click on the multiple input file icon. This will let you use shift, command or control on your keyboard to select multiple datasets from your current history to be run through the workflow.
You can modify any options available to the tools in your workflow by clicking on each of the tools within the workflow. For example, clicking the Tokenize Text tool will allow you to select or deselect either Lowercase all tokens or Remove punctuation. Clicking on the Stemmer tool will let you choose which stemmer algorithm to use. Modifying these settings at runtime will override the settings configured in the saved workflow, but it will not change the settings in the saved workflow itself. That is, if a workflow has the lowercase option set in the tokenizer and it is unset at runtime, the next time you run the workflow the lowercase option will default to being set.
The last checkbox before the Run workflow button allows you to direct the output files to a new history, which may be helpful for you to separate your analyses into different histories.

If you run your workflow over multiple input datasets, then checking this checkbox will create a new history for each input dataset, rather than outputting all results to the same new history.
Click Run workflow. You should see a message telling you that your workflow has been added to the queue. Depending on how large and complex the workflow and input datafiles are, it may take some time to appear in the history and to run. You may also need to switch to the correct history if you opted to send the results to a new history.
Complex workflows
It is also possible to direct the output of one tool into multiple tools in workflows. This functionality allows you to define complex workflows that have multiple paths. To join one tool to a second tool, simply drag a second pipeline from the output connector into another tool’s input connector, and repeat as many times as necessary.
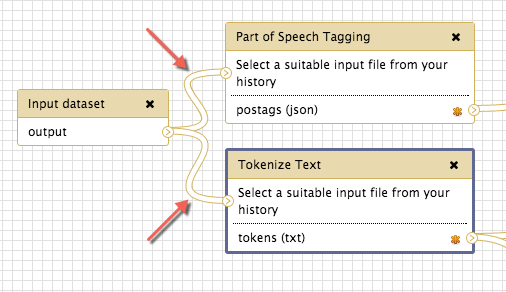
This is handy if you want multiple different analyses over the same dataset, for example if you want to count the frequency of words in a text that have been stemmed against those that have not.
| Tutorial Task 10: Edit the workflow that you created in the previous task, and add the different combinations of tools that you tried in the Module 3 tasks. Ensure that the output dataset of each tool has a meaningful name. Note: The order of the tools will be: Input dataset into Tokenize Text into Part of Speech Tagging into Frequency List, Input dataset into Tokenize Text into Stemmer into Frequency List, and Input dataset into Tokenize Text into Frequency List.Mark only the three Frequency List tools as Workflow Outputs, and ensure that each tool has a Rename Dataset action set, with a variable like #{input1}-[tool] to name the outputs with the tool name suffixed to the input dataset name. 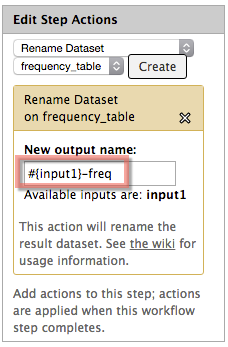 Once you have correctly configured your workflow, save it (from the gear icon in the top left) and run it over one of your datasets. | |—|
Once you have correctly configured your workflow, save it (from the gear icon in the top left) and run it over one of your datasets. | |—|
Sharing Workflows
Another benefit of saving the steps of your analysis in a workflow is that you can share them with other Alveo users or publish them so that anyone who uses Alveo can run them over their own datasets. Similarly, you can access the workflows that other Alveo users have made available.
To share your workflow, go to the Workflow Management View and you should see the workflow you created earlier. Click on the drop-down menu next to this workflow, but instead of selecting Run or Edit, select Share. You will see a screen with three options for sharing: Make Workflow Accessible via Link, Make Workflow Accessible and Publish and Share with a User.

Clicking Make Workflow Accessible via Link will give you a URL that you can then email to other users, or publish somewhere – such as in a research paper – to allow others to repeat and verify your findings. Clicking Make Workflow Accessible and Publish will allow anyone else using Alveo to import your workflow and run it on their own data. It will also provide a link that you can send or publish, as with the first option. After you have shared your workflow using either of these methods, you can also unshare it by selecting Unpublish Workflow or Disable Access to Workflow via Link and Unpublish.
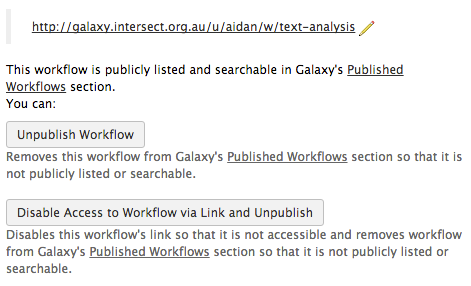
Lastly, clicking Share with a User will open a dialogue box in which you can enter the email address of another Alveo user so that the Workflow will be visible to both you and them. This last option is useful if you work with a research group and want your analyses to be replicated and reused by your peers, but not by anyone else.
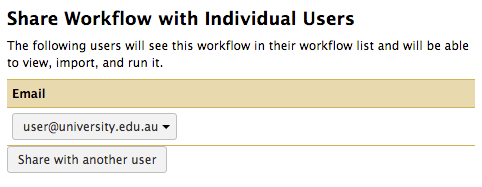
If you want to stop sharing the workflow with the user, do so by clicking their name and selecting Unshare.
Using others’ Workflows
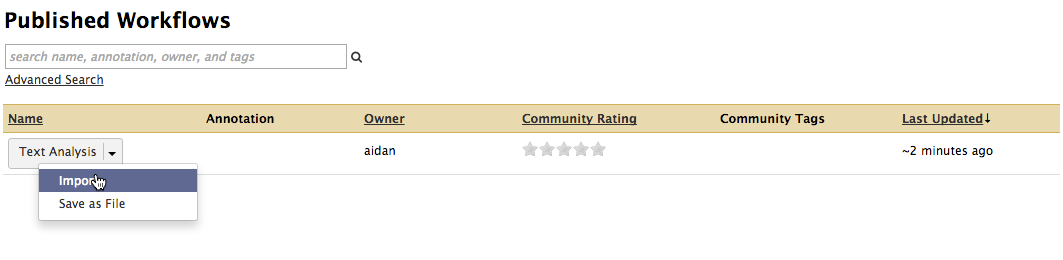
To access workflows that other researchers have published, go to the Shared Data menu and select Published Workflows. This page will list all the workflows that other users of Galaxy have published. When you find a Workflow that you want to use, click on its name and select Import. It will then appear in your list of Workflows and you will be able to run it on your own data, as described in the section above.
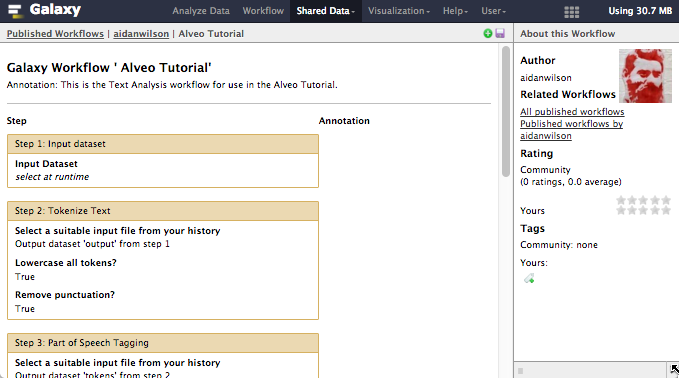
If someone has shared a workflow with you using a link, you will have to go through a similar process to import the workflow into your Galaxy account. When clicking the link, Galaxy will open and display the workflow with tis steps and annotations in the main window, and information about the workflow author in the right sidebar.
At the top-right of the main window are two buttons, one to Import the workflow into your Galaxy account, and the other to Save the workflow to your local machine. Again, if you click Import, it will appear in your list of Workflows and you will be able to run it on your own data.
| Tutorial Task 11: Find and import the Workflow called Alveo Tutorial using one of the two methods above and run it over the three datasets that you have been working on throughout this tutorial: Cooee_1780s, Cooee_1880s and ACE_1980s. This workflow should be the same as the one you created in Tutorial Task 10. Verify that the results you have from your own workflow are the same as those from the Alveo Tutorial workflow. If your results differ, you may want to check to see if the workflows have any differences in the order or configuration of each of the tools.The workflow you imported should look like this: 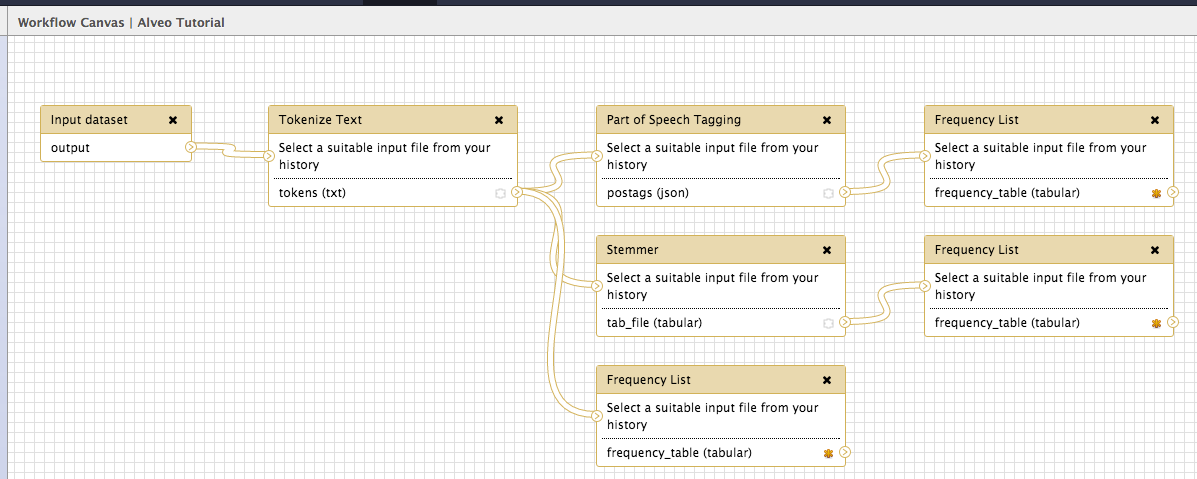 Note: Remember that in order to run multiple datasets through a single workflow, you need to enable selection of multiple input files when running the workflow, by clicking the icon denoting a stack of multiple pages.
Note: Remember that in order to run multiple datasets through a single workflow, you need to enable selection of multiple input files when running the workflow, by clicking the icon denoting a stack of multiple pages. 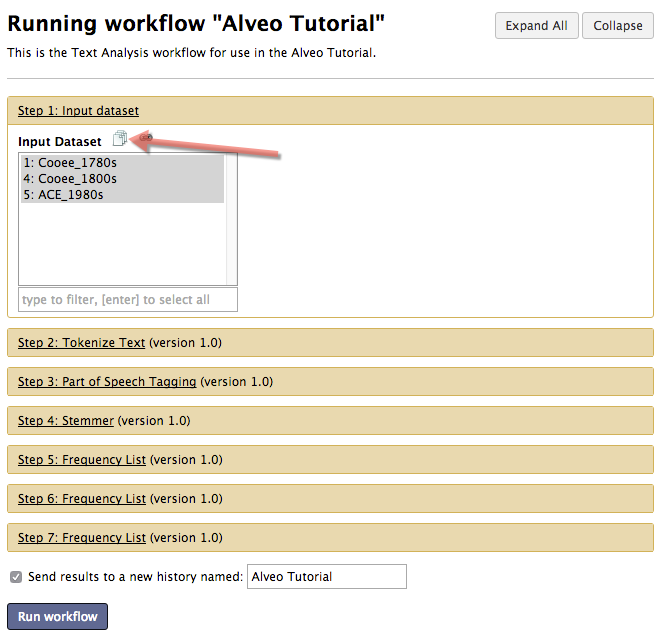 | |—|
| |—|