
This is Part 3 of a four-part tutorial in using Alveo. You can find the outline of the tutorial, and links to the other three parts on the Tutorials page. This Part will cover the suite of text manipulation and language analysis tools available in Galaxy, and how to run datasets through a series of tools.
Introduction to Tools
The power of Galaxy is in the Toolshed – the sidebar on the left of the page which contains processors and scripts that you can use to do things to your datasets, such as manipulate them, analyse them, create output files and download them. You can also upload additional data from your own computer, or import data from online sources. Uploading or importing additional data into Galaxy is useful if you want to compare your analysis of data from Alveo with other sources that you can find on the internet, or which you may have on your own computer.
The tools in the toolshed can also be strung together in Workflows, and these workflows can be run over a number of data files at once, allowing you to repeat experiments on different datasets at different times with ease. You will learn how to define and run workflows in Part 4, but first, this Part will introduce you to the tools and how to use them individually.
Data Uploading/Importing tools
Click on Get Data and you will see a number of tools for data upload and importing, including Alveo Data Importer, Concatenator, and Upload File. With the Upload File tool, you can paste text into a text box, or upload a file from your own computer, either by navigating to it or drag-and-drop. The Concatenator tool will allow you to insert a list of URLs that point to textual data and concatenate that text into a single dataset for analysis in Galaxy.
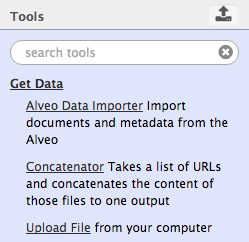
In Part 2 we imported lists of data from Alveo to Galaxy, using the Use list in Galaxy option. This worked by initiating the Alveo Data Importer tool in Galaxy and automatically inserting the item list URL and your API key from Alveo. You can ignore this tool and continue to push datasets from Alveo to Galaxy using the technique shown already, as it means you do not have to go and find your API key or remember the list URL. However, if you want to import files from Alveo in this way, you can get the list URL from the address bar when you are viewing a list, and you can retrieve your API key by clicking on your username in the top-right corner, selecting API key, and Copy to Clipboard.
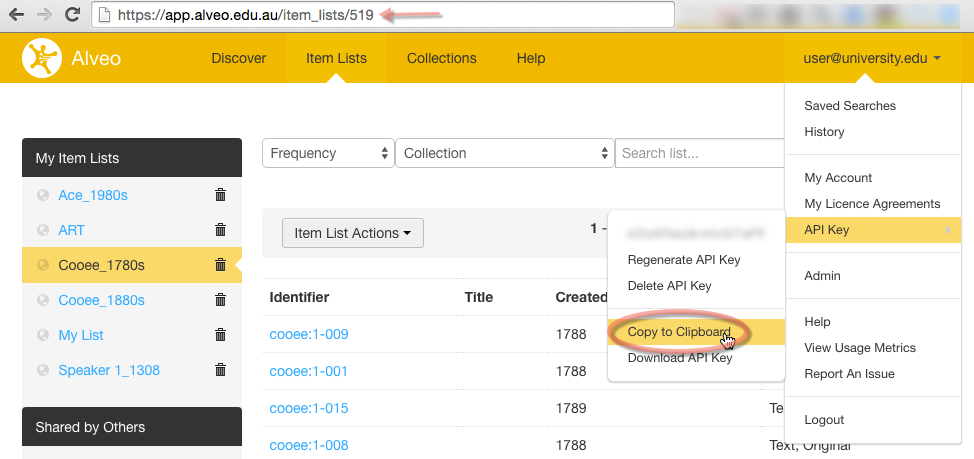
We will now upload some data into Galaxy using the Upload File tool.
First, click the Upload File in the toolshed. A dialogue box will open allowing you to drag-and-drop files from your computer. At the bottom of this dialogue box is an option to Paste/Fetch data, which allows you to either paste data from your clipboard, or upload it directly from the web.
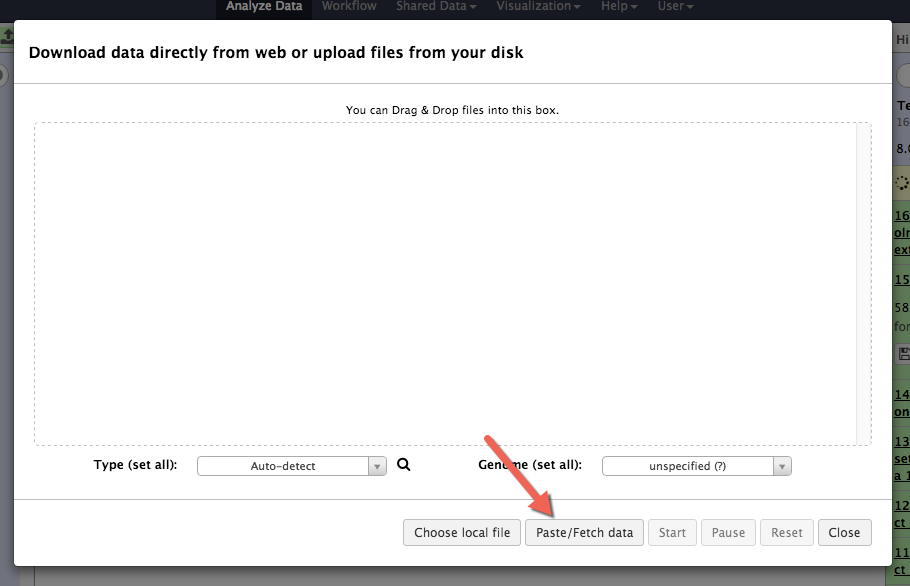
When you click Paste/Fetch data, you will see a field in which you can either paste some copied text straight into Alveo, or enter a URL.
Click Paste/Fetch data and, in the text box, type (or copy and paste) the following sentence.
The rain in Spain falls mainly on the plain.
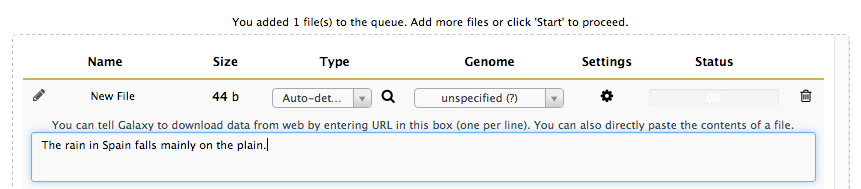
Now click Start. Galaxy will convert your input into a text dataset that can be analysed or manipulated with the tools.
Data Analysis
The toolshed also contains tools that you can use to analyse data and output derivative datasets for later analysis. These tools include sentence parsers, part-of-speech (POS) taggers, tokenizers, stemmers and many more, and sometimes the output of one tool can be used as the input of another tool, as demonstrated later in the tutorial. Working with the tools will require lots of practice and plenty of trial and error to find out how each tool works, what its options are, and what its output looks like.
Using the simple sentence we just imported, we will go through some of the data analysis tools. Select the Part of Speech Tagging tool from the Text Analysis section of the toolshed. The sentence you uploaded will be in a dataset called Pasted Entry, and it should be the last dataset in your current history. When you select the Part of Speech Tagging tool, the Pasted Entry dataset will be automatically selected. Verify this, and give the output dataset a meaningful name, such as Spain-POS, and click Execute.
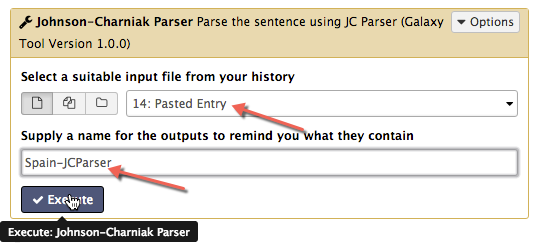
The Part of Speech Tagging tool will analyse the dataset through a complex algorithm to compute its part of speech (POS), that is, whether it is a verb or a noun or something else, and append a POS tag to each word in the text. The output of this tool is a new dataset in the history which contains the same text, but with each word appended by its part of speech, as shown below.
The/DT rain/NN in/IN Spain/NNP falls/VBZ mainly/RB on/IN the/DT plain/NN ./.
The codes used for the POS tags can be a little obscure. To understand the codes and what part of speech each one refers to, you can find the list of codes and their meanings here.
Stringing tools together
We will use a number of text analysis tools from the Text Analysis collection of tools to run some analysis over our collections. First, make sure you are working with the Text Analysis history, which is where you saved the concatenated text files in the last Part of the tutorial.
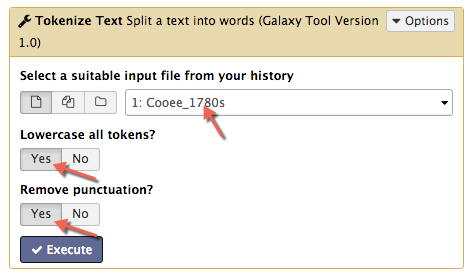
Select the Tokenize Text tool. This tool splits the input file so that each word (or token) occurs on a new line. Make sure both options Lowercase all tokens? and Remove punctuation? are checked, and then select the Cooee_1780s dataset from the drop-down list as the input. Hit Execute.
The process will show up in the history sidebar as a numbered job. It will start as grey, indicating the job has been queued but not commenced, then yellow, indicating that the job is running, and finally green to indicate that it is complete.
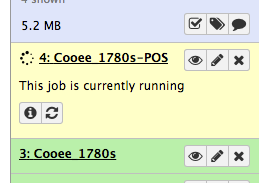
When it is complete and has turned green in the history, you can click on the eye icon to view the result.
Next, run the tokenized text file through the Part of Speech Tagging tool. Select the Part of Speech tool from the toolkit, and make sure that the last output dataset, the tokenized text file, is selected as the input file. Change the output name to something meaningful, such as Cooee_1780s-tokens-POS. Finally, click Execute.
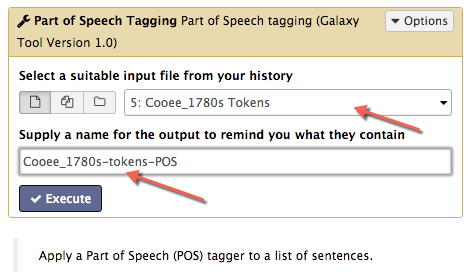
You should now have a dataset that has been through two tools; it has gone through the tokenizer and the POS tagger. The resulting dataset has no capital letters and no punctuation, and each word is tagged with its part of speech.
The next tool we can use on this dataset is the Frequency List tool from the Statistics tool collection, which takes a text, counts the occurrence of each unique word and outputs a list of words, the number of times each occurs, and each word’s frequency in the text as a percentage. Make sure you select the part-of-speech tagged text as the input file, change the output name to something meaningful (such as Cooee_1780s-tokens-POS-freq), and click Execute.
Have a look at the output file and you will see the words with their POS tags and how frequent they are in the text.
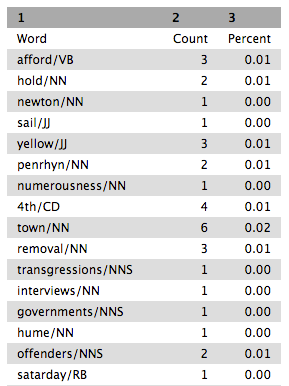
Notice that this list is not sorted in any way. In order to see which words are most frequent in this dataset, this frequency list will need to be sorted. To do this, use the Sort tool from the Filter and Sort tool collection. This tool can sort tab delimited data (which the output of the frequency list is) either numerically or alphabetically, either ascending or descending, for any column. To sort this frequency list numerically, choose either column 2 or 3 (both will have the same effect), select Numerical sort, and Descending order (so that the highest numbers, the highest frequency, will be sorted at the top), and click Execute.
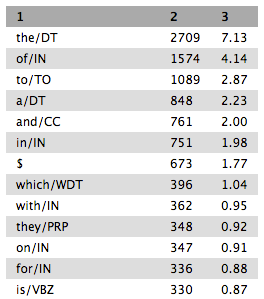
You should now have a dataset that lists the most frequent words in different parts of speech, and how many times they occur in the text. Take a look through the output and see if you can find any words that occur twice. You may want to use your browser’s search function to find words such as that or who to see the difference in the frequency of their use as different parts of speech.
| Tutorial Task 6: Run the Frequency List tool over the Cooee_1780s-tokens dataset, without putting it through the Part of Speech Tagging tool first, then sort it with the Sort tool, and compare the results with Cooee_1780s-tokens-POS-freq. Note: You are able to use datasets that have previously been used in other tools. Look for the word ‘that’ in the two datasets and see if you notice a difference. | |—|
The Stemmer tool takes each word and outputs only its stem, that is, the central part of the word that is common across all different forms. For example, thinking when run through the Stemmer tool will be output as think and unfathomable will become fathom. The Stemmer tool therefore allows you to compare words in a text irrespective of differences such as tense or number. Running a text through the Stemmer tool and then through the Frequency List tool will give you the most commonly occurring underlying stems.
| Tutorial Task 7: Run the same original data file, Cooee_1780s, through the Tokenize Text tool, then the Stemmer tool, the Frequency List tool, and finally the Sort tool and compare the result with the two previous results. Note: The Stemmer Tool has multiple algorithms: Lancaster, Porter and Snowball. Each of these will produce slightly different results, especially for uncommon words. It is worth trying out your data analysis with different Stemmer algorithms and seeing which produces the best results. | |—|
What we have now done is run a single dataset through a combination of several tools in a precise order. This is effectively a Workflow. In Part 4, we will learn how to define a workflow so that it can be reused, meaning our analysis can be repeated by others, or run again over more datasets in future.
Proceed to Part 4: Workflows.